Verbalized Sampling – oder: Warum einem LLM die Ideen ausgehen

Ich habe letzte Woche Gemini gebeten, Text-Assets für Google Ads zu generieren. Input: strukturiertes JSON mit Persona, Zielgruppe, USPs, etc. – sauber gebriefed, nichts vergessen. Nach dem dritten oder vierten Durchlauf wurden die Headlines strukturell immer ähnlicher, die Variationen fühlten sich an wie Synonymwörter desselben Satzes. Kein einzelner Output war schlecht. Aber zusammen waren sie: so ziemlich eins.
Das hat einen Namen – und seit Oktober letzten Jahres gibt es eine Methode dagegen, die tatsächlich funktioniert. Zumindest teilweise. Und das ist schon mehr, als die meisten Prompt-Tricks der letzten zwölf Monate versprechen konnten.
TL;DR
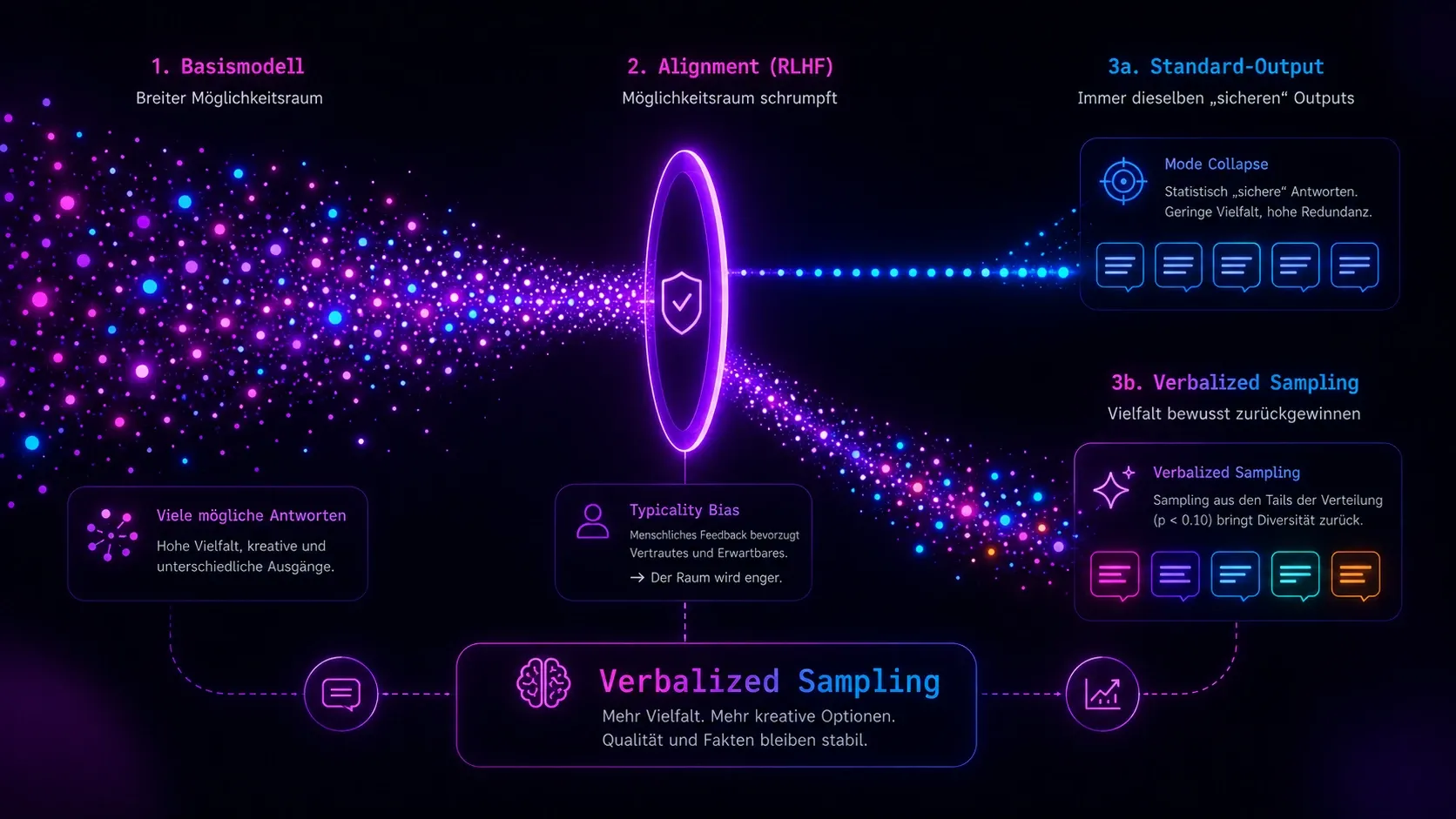
Wer ein LLM mehrfach dasselbe kreative Ding generieren lässt – Ad Copy, Headlines, Storys –, kennt den Effekt. Die Outputs werden mit jedem Durchlauf gleicher, andere Wörter, dasselbe Skelett. Der Name dafür ist Mode Collapse. Die Ursache liegt nicht am Modell selbst, sondern am Alignment – RLHF optimiert auf die erwartbarste statt die interessanteste Antwort (Typicality Bias).
Verbalized Sampling (VS) setzt an einer erfrischend simplen Stelle an. Statt nach einer Antwort fragt man das Modell nach einer Verteilung mehrerer Antworten – explizit aus den unwahrscheinlicheren Regionen (probability < 0.10).
- Was es bringt:Was es bringt: Laut Paper das 1,6- bis 2,1-fache an Diversität gegenüber direktem Prompting, bei stabiler Qualität. Forschungs-Sternchen inklusive, die Methodik ist aber solide.
- Was es kostet: Die Tokens skalieren linear mit der Zahl der Kandidaten, und enger JSON-Input plus strenges Briefing beschleunigen genau den Collapse, gegen den VS ankämpft.
- Was es nicht löst: Halluzinationen. Fünf falsche Antworten statt einer sind kein Fortschritt.
Trainingsfrei, modell-agnostisch, in zehn Minuten integriert. Ob der Token-Aufpreis den Diversitätsgewinn rechtfertigt, beantwortet nur die eigene Pipeline.
Das Problem heißt Mode Collapse, und es liegt nicht am Modell allein
Wenn ein LLM nach dem Pre-Training durch RLHF oder ähnliche Alignment-Verfahren läuft, schrumpft sein Möglichkeitsraum spürbar zusammen. Das Basismodell kennt eine breite Verteilung möglicher Antworten – nach dem Alignment landet es immer öfter bei denselben, statistisch „sicheren" Outputs.
Der Grund dafür ist, laut einem Paper von Zhang et al. von Northeastern, Stanford und West Virginia University, kein algorithmisches Problem, sondern ein Datenproblem: Typicality Bias. Menschliche Annotatoren bevorzugen beim Bewerten von Antworten systematisch das Vertraute, Erwartbare, Glatte. Was als „gute Antwort“ markiert wird, ist meistens die prototypischste – nicht die kreativste. Das Alignment-Verfahren lernt genau das: Gib die wahrscheinlichste, nicht die interessanteste Antwort.
Im Coding-Kontext fällt das kaum auf. Bei kreativen Aufgaben – Ad Copy, Storys, Brainstorming, synthetische Trainingsdaten – ist es ein echtes Produktionsproblem. Und Temperature hochzudrehen hilft nur begrenzt: Man bekommt mehr Zufall, nicht mehr Diversität.
Was Verbalized Sampling tut
Die Kernidee des Papers ist erfrischend simpel: Statt das Modell nach einer Antwort zu fragen, fordert man es auf, eine Verteilung zu produzieren – also mehrere Antworten zusammen mit geschätzten Wahrscheinlichkeiten.
Der Prompt-Kern, direkt aus dem Paper:
<instructions>
Generate 5 responses to the user query, each within a separate <response> tag.
Each <response> must include a <text> and a numeric <probability>.
Please sample at random from the tails of the distribution,
such that the probability of each response is less than 0.10.
</instructions>
Tell me a short story about a bear.Was hier passiert: Das Modell wird gezwungen, nicht den einen wahrscheinlichsten Output zu produzieren, sondern eine Auswahl – und zwar explizit aus den unwahrscheinlicheren Regionen seiner internen Verteilung (probability < 0.10). Das verschiebt den Output weg von den durch Alignment verstärkten Standardantworten.
Die Zahlen aus dem Paper: VS steigert die Diversität im kreativen Schreiben um das 1,6- bis 2,1-fache gegenüber direktem Prompting und stellt 66,8 Prozent der ursprünglichen Basismodell-Diversität wieder her – gegenüber 23,8 Prozent bei direktem Prompting. Qualität und faktische Genauigkeit bleiben dabei stabil. Wer die Zahlen einordnen will: Das sind herstellerunabhängige Messungen aus dem Paper selbst, also trotzdem mit dem üblichen Forschungs-Sternchen zu lesen – aber die Methodik ist solide, das Paper auf arXiv einsehbar.
pip install verbalized-samplingDie API des Packages ist tatsächlich so schlank, wie das klingen soll:
from verbalized_sampling import verbalize
# Verteilung generieren, k=5 Kandidaten, tau=0.10 als Wahrscheinlichkeitsschwelle
dist = verbalize(
"Schreibe eine Google Ads Headline für einen lokalen Steuerberater",
k=5,
tau=0.10,
temperature=0.9
)
# Zufällig aus der Verteilung samplen
result = dist.sample(seed=42)
print(result.text)Oder man will alle fünf Kandidaten sehen – zum Beispiel, um manuell die beste zu wählen oder alle fünf als Varianten weiterzuverarbeiten:
for candidate in dist:
print(f"[p={candidate.probability:.2f}] {candidate.text}")Das Package unterstützt OpenAI, Anthropic, Gemini und Modelle via OpenRouter, ist modell-agnostisch und orthogonal zu den klassischen Sampling-Parametern. Sprich: Temperature und Top-p funktionieren wie gewohnt, VS arbeitet eine Ebene darüber. Das GitHub-Repo und die Projektseite liefern weitere Beispiele inklusive Colab-Notebook.
Wo das in der Praxis an Grenzen stößt
Jetzt der ehrliche Teil – und der ist relevanter als die Paper-Zahlen.
1. Schönheitsfehler: Die Wahrscheinlichkeiten sind keine echten Wahrscheinlichkeiten. Das Modell schreibt eine Zahl in den Output, weil der Prompt eine Zahl fordert. Ob diese Zahl die internen Token-Verteilungen korrekt widerspiegelt, ist eine andere Frage. Man bekommt ein Verhalten, das nach Verteilung aussieht – kein Messinstrument. Für nachgelagerte Entscheidungen, die auf diesen Werten aufbauen, wäre ich vorsichtig.
2. Schönheitsfehler: Mode Collapse kann rekursiv auftreten – und enge Constraints beschleunigen das. Was ich bei meinem Ad-Copy-Test mit Gemini beobachtet habe: Die Varianten wurden mit jedem Batch nicht schlechter, aber gleicher – fünf Überschriften mit anderen Wörtern, demselben narrativen Skelett. Das ist keine Frage des Kontextverlusts oder eines Drifts im technischen Sinne, sondern Alignment-bedingte Konvergenz: Je enger der Möglichkeitsraum durch Vorgaben wird, desto schneller landet das Modell bei seinen statistisch wahrscheinlichsten Moves. Strukturiertes JSON als Input-Format macht das noch ausgeprägter – ein Teil der Modellkapazität geht in die Formatkonformität, der kreative Spielraum schrumpft entsprechend weiter. VS mildert das, beseitigt es nicht. Wenn das Modell unter drei gleichzeitigen Constraints (Alignment, enge Briefing-Vorgaben, JSON-Output-Format) konvergiert, kämpft VS gegen alle drei auf einmal.
3. Schönheitsfehler: Die Inferenzkosten skalieren linear mit k. Fünf Antworten kosten grob fünfmal so viele Tokens wie eine. Bei Einzelanfragen irrelevant. Bei Pipelines, die tausende Generierungen am Tag verarbeiten, ist das ein echter Posten in der Wirtschaftlichkeitsrechnung.
4. Schönheitsfehler: User-seitige Last. Aus Produktsicht ist „hier sind fünf Optionen, wähl eine“ nicht immer ein Geschenk. In manchen Workflows – Brainstorming, Variantenproduktion – ist genau das gewollt. In anderen will die Nutzerin eine Antwort, kein Auswahlmenü. Das umgebende System muss das lösen, nicht VS.
Und was VS explizit nicht löst: Halluzinationen. Wer fünf falsche Antworten statt einer falschen Antwort produziert, hat keinen Fortschritt gemacht.
Wofür es sich lohnt – und wofür nicht
Klar anwendbar: kreatives Schreiben, Brainstorming, Slogan- und Ad-Copy-Generierung, Dialogsimulation, synthetische Trainingsdaten, Open-Ended QA. Überall dort, wo Mode Collapse ein echtes Produktionsproblem ist und nicht nur ein theoretisches Ärgernis.
Weniger relevant: klassische Frage-Antwort-Szenarien, Code-Generierung mit klaren Spezifikationen, faktenkritische Auskünfte, Tasks, wo Konsistenz wichtiger ist als Vielfalt. Niemand will fünf SQL-Queries sehen, von denen drei subtil falsch sind.
Mein Take: VS ist kein Fix für Mode Collapse – es ist ein Workaround, der die Symptome lindert. Die eigentliche Ursache, ein Alignment-Verfahren, das Vielfalt systematisch wegoptimiert, bleibt unangetastet. Wer das strukturell beheben will, muss am Training ansetzen, nicht am Prompt.
Für den Werkzeugkasten reicht das trotzdem. Die Methode ist trainingsfrei, modell-agnostisch, in zehn Minuten integriert – und liefert messbar mehr Diversität als Temperature-Geschraube. Bei meiner Ad-Copy-Pipeline werde ich VS in den nächsten Wochen ernsthafter testen, mit klareren Abbruchkriterien für den Drift-Fall. Ob der Token-Aufpreis den Qualitätsgewinn rechtfertigt, ist genau die Frage, die sich nur in der Praxis beantworten lässt.
Quellen: