Spec-Driven Generation ist kein Prompt-Trick mehr

Das wird etwas länger heute – die Recherche war sehr ergiebig und obendrauf kann ich auch noch reichlich eigene Erfahrungswerte beisteuern.
Der Holzhammer kurz und bündig: Spec-Driven Generation – kurz SDG, in der überlappenden Coding-Variante meist als Spec-Driven Development (SDD) bezeichnet – ist eines der Themen, bei denen man 2026 zwei Sätze von zwei Praktikern hört und sich fragt, ob die überhaupt vom gleichen Ding reden. Die einen schreiben „Specs are the new source of truth". Die anderen schreiben „Waterfall mit frischem Lack". Beide Seiten haben Belege, beide Seiten haben recht – und das ist genau der Punkt, an dem es interessant wird.
Im Beitrag zu Constraint-Based Prompting habe ich für eine verwandte Technik argumentiert, dass sie auf kleineren Modellen State of the Art bleibt und auf Frontier-Reasonern messbar Overhead erzeugt. Bei SDG ist die Lage komplexer, weil hier nicht nur die Modellgröße zählt. Es kommen zwei weitere Achsen dazu, die das Bild kippen. Wer SDG pauschal verteidigt oder pauschal beerdigt, übersieht beide.
TL;DR
Spec-Driven Generation – strukturierte, versionierte Spezifikationen statt Mega-Prompts – hat sich 2026 vom Prompt-Trick zum Architektur-Pattern gemausert. Die Formate dahinter (GitHub Spec Kit, AGENTS.md, Anthropic Skills) sind im letzten Jahr aus dem Experiment in eine erste Reifephase gerutscht.
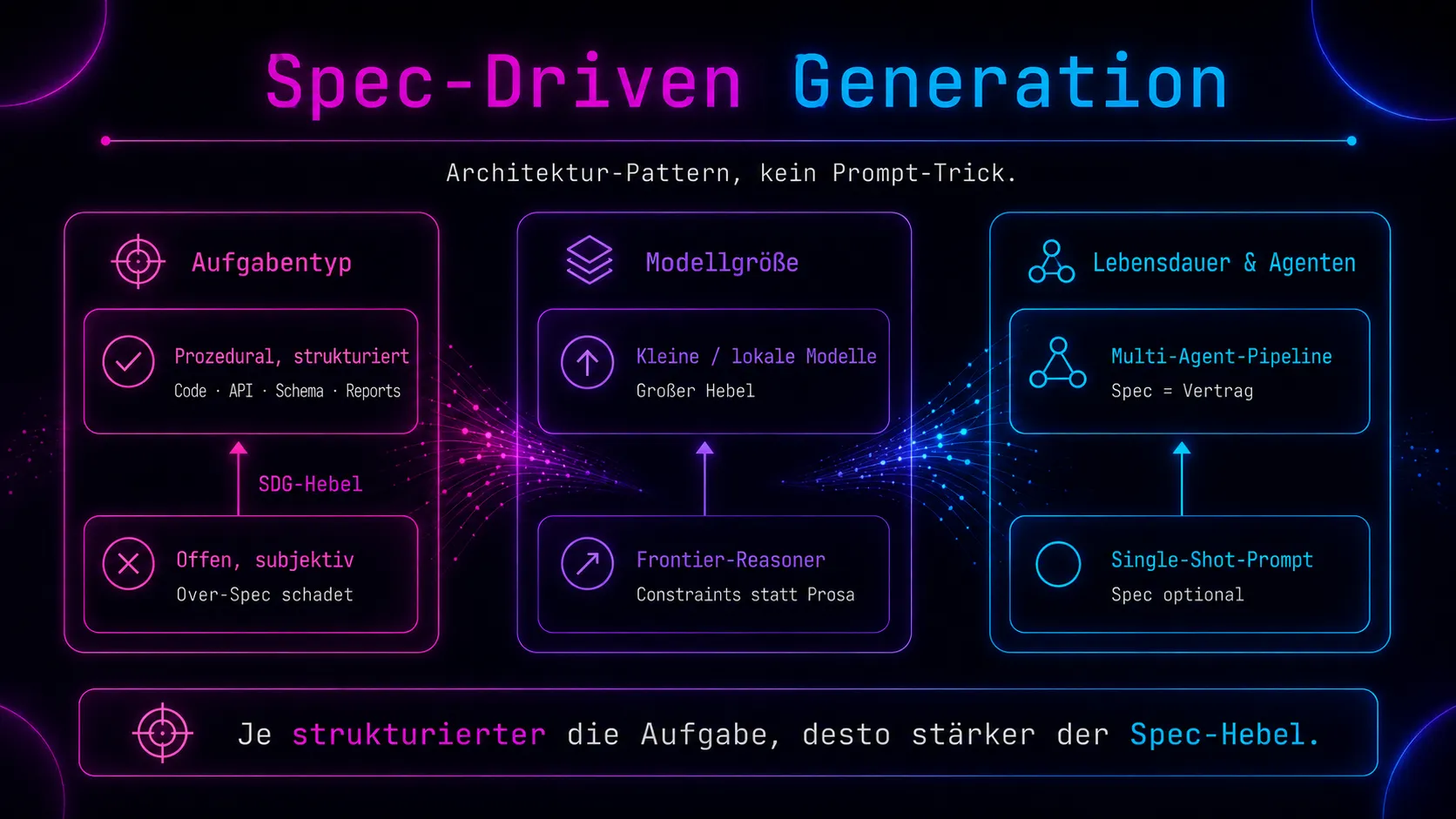
Ob das für dich ein Hebel oder ein Klotz am Bein ist, entscheiden drei Achsen:
- Aufgabentyp: Lässt sich das Ergebnis über nüchterne Acceptance Criteria prüfen, hilft eine Spec. Bei offenen, deliberativen Aufgaben schadet Over-Spec eher.
- Modellgröße: Kleine Modelle profitieren überproportional. Bei Frontier-Reasonern ist der Hebel kleiner – und verschiebt sich auf Constraints und Negativbeispiele statt auf Schritt-für-Schritt-Anleitungen.
- Lebensdauer und Mehragentigkeit: Sobald Outputs zwischen Agenten wandern, ist die Spec kein Briefing mehr, sondern Vertrag.
Die Studienlage stützt die Trennlinie: Klassische Prompt-Tricks wie Chain-of-Thought werden auf Reasoning-Modellen oft kontraproduktiv – eine saubere Spec mit Edge-Cases nicht. Die Frage ist nicht der Modell-Stand, sondern wo deine Aufgabe auf den drei Achsen liegt.
Was Spec-Driven Generation eigentlich ist – und was nicht
Die Grundidee lässt sich kompakt fassen: Statt einem Modell oder Agenten eine Aufgabe als Prompt zu geben, schreibst du eine strukturierte Spezifikation – das Was, die Constraints, die Acceptance Criteria, optional die Architektur – und das Modell generiert daraus den Output. Die Spec ist versioniert, prüfbar, weitergebbar. Sie ist nicht das Prompt; sie ist ein Artefakt, das das Prompt erst möglich macht.
Das Pattern existiert in mehreren Inkarnationen:
In der Coding-Welt ist es das GitHub Spec Kit, im September 2025 als Open-Source-Toolkit veröffentlicht und mittlerweile bei Version 0.8.7 mit über 90.000 Stars und 8.000 Forks auf GitHub. Vier Phasen: /constitution (nicht verhandelbare Regeln), /specify (Was und Warum), /plan (technischer Plan), /tasks plus /implement (kleinteilige, testbare Aufgaben). Der zentrale Move ist im Repo unverblümt formuliert:
Specifications don't serve code – code serves specifications.
In der Agenten-Welt ist es AGENTS.md, im August 2025 von OpenAI veröffentlicht und seitdem in mehr als 60.000 Open-Source-Projekten adoptiert – Codex, Cursor, Devin, Factory, Gemini CLI, GitHub Copilot, Jules, VS Code. Im Dezember 2025 hat OpenAI das Format an die Linux Foundation gespendet, gemeinsam mit Anthropics MCP und Blocks goose, als Gründungsbeitrag der Agentic AI Foundation. AGENTS.md ist im Kern ein README für Agenten: Build-Schritte, Test-Konventionen, Architektur-Constraints, Domain-Vokabular – maschinenlesbar und projekt-skaliert.
In der Capability-Welt sind es Anthropic Skills, im Oktober 2025 als SKILL.md eingeführt und im Dezember 2025 als offener Standard auf agentskills.io freigegeben. Ein Skill ist ein Ordner mit einer SKILL.md (YAML-Frontmatter plus Markdown-Body), optional ergänzt durch Scripts, Templates, Referenzdokumente. Das clevere Detail ist progressive disclosure: Nur die Metadaten wandern in den Initial-Context, der Body wird erst geladen, wenn das Modell den Skill aktiviert. Inzwischen wird das Format von Codex, Cursor, VS Code, Gemini CLI, Kiro und einer Reihe weiterer Tools unterstützt.
Was diese drei Formate gemeinsam haben: Sie ersetzen das single mega prompt durch persistente, versionierte Artefakte. Sie machen das „Was“ explizit und überprüfbar. Und sie behandeln das Modell weniger wie eine Suchmaschine und mehr wie einen pedantischen Pair-Programmer, der unzweideutige Instruktionen braucht.
Die Frage, die alle umtreibt: Brauchen Reasoning-Modelle das überhaupt noch?
Hier wird es spannend, und hier liegt das Missverständnis. Wer Specs als Prompt-Trick versteht – als Methode, dem Modell beim Denken zu helfen – kann sich mit einer berechtigten Frage zurücklehnen: Wozu, wenn das Modell selbst denkt?
Die empirische Antwort ist nicht eindeutig, aber sie ist klar genug, um eine differenzierte These zu stützen. Zwei Studien stehen sich gegenüber, und beide haben recht – nur für unterschiedliche Aufgabentypen.
Auf der einen Seite Wang et al., „Do Advanced Language Models Eliminate the Need for Prompt Engineering in Software Engineering?" (ACM TOSEM, 2024). Das Setup vergleicht GPT-4o (Non-Reasoning) und o1/o1-mini (Reasoning) auf Code-Generation, Code-Translation und Code-Summarization mit elf etablierten Prompt-Engineering-Techniken: Few-Shot, Chain-of-Thought, Critique-Prompting, Multi-Agent. Der Befund:
Prompt engineering techniques developed for earlier LLMs may provide diminished benefits or even hinder performance when applied to advanced models.
Bei o1-mini bringen viele klassische Tricks nichts mehr oder sogar negative Effekte. Reasoning ersetzt klassisches Prompt-Engineering.
Auf der anderen Seite Olivia Kim, „DETAIL Matters“ (Emory University, Dezember 2025). 30 Reasoning-Tasks, drei Spezifitätsstufen, GPT-4 und O3-mini. Befund: Spezifität verbessert die Genauigkeit deutlich für prozedurale Aufgaben (Mathematical Word Problems: +0,47 Accuracy zwischen vagem und detailliertem Prompt, Logic Puzzles: +0,36, Code Understanding: +0,29), aber kaum oder negativ für offene Aufgaben (Decision-Making: +0,02, in Einzelfällen schlechter). Das Paper formuliert es so:
Specificity improves accuracy, especially for smaller models and procedural tasks", und für Decision-Making sei „over-specification may constrain rather than help model reasoning.
Beides ist konsistent, wenn man die Begriffe sauber zieht. Prompt-Engineering-Tricks wie CoT-Aufforderungen und Few-Shot werden auf Reasoning-Modellen tatsächlich oft kontraproduktiv. Strukturierte Aufgabenbeschreibung – die Spec – nicht. Sie wird, je nach Aufgabentyp, sogar wertvoller. Wer einem Reasoning-Modell „denk Schritt für Schritt“ hinzufügt, schadet meistens. Wer dem Modell eine saubere Spec mit Acceptance Criteria, Edge Cases und Constraints gibt, hilft.
Das ist die Inversion, die diesen Beitrag trägt: SDG ist 2026 kein Prompt-Trick mehr, sondern ein Architektur-Pattern. Der Hebel hat sich verschoben – von „dem Modell beim Denken helfen“ zu „dem Modell den Vertrag geben“.
Drei Achsen, die entscheiden
Die Leitthese „SDG bleibt relevant“ ist haltbar, aber sie braucht Differenzierungen. Drei Achsen entscheiden, ob SDG für deinen Fall ein Hebel oder ein Klotz am Bein ist.
Erstens: der Aufgabentyp. Prozedural, strukturiert, mit eindeutigen Acceptance Criteria – SDG funktioniert. Code-Generation, API-Design, Datenextraktion, Schema-Migrationen, Berichtsgenerierung mit regulatorischen Pflichtfeldern. Sobald die Aufgabe semi-formal spezifizierbar ist, also wenn du sagen kannst „das Ergebnis ist korrekt, wenn X, Y und Z erfüllt sind“, profitiert sie. Sobald sie offen, subjektiv oder ethisch-deliberativ ist, schadet Over-Spec eher, als dass sie hilft. Des Pudels Kern: Wenn du die Acceptance Criteria nicht in drei nüchternen Bullet-Points formulieren kannst, ist SDG für diese Aufgabe das falsche Werkzeug – ganz einfach.
Zweitens: die Modellgröße. Hier wiederholt sich das CBP-Muster: Kleinere Modelle profitieren überproportional von expliziten Specs, größere weniger linear. Kims Befund („especially for smaller models“) deckt sich mit dem, was MIT CSAIL im Dezember 2025 mit DisCIPL gezeigt hat – ein Verbund aus Llama-3.2-1B-Modellen, der via GPT-4o-Planner und expliziten Constraint-Spezifikationen die Genauigkeit aktueller Reasoning-Systeme erreicht, bei 80,2 % geringeren Kosten gegenüber o1 (nur ist o1 eben mittlerweile deprecated). Der Hebel ist riesig, wenn du lokale, kleine oder kostengetriebene Modelle einsetzt. Bei Frontier-Reasonern wie Claude Opus 4.x oder GPT-5 ist er kleiner, aber er ist da – nur eben verschoben auf Constraints und Negativbeispiele statt auf Schritt-für-Schritt-Anleitungen.
Letzteres mit einem ehrlichen und erheblichen Pferdefuß: Beide Studien arbeiten mit Modellen (o1/o1-mini, O3-mini, GPT-4o), die im Mai 2026 nicht mehr Frontier oder teils nicht mehr verfügbar sind. Für die aktuelle Generation – GPT-5.5 Thinking, Claude Opus 4.8, Gemini 3 Pro – fehlen entsprechende systematische Untersuchungen noch. Die Befunde sind als Muster übertragbar, nicht als absolute Zahlen.
Drittens: Lebensdauer und Mehragentigkeit. Hier wird die These am deutlichsten. Ein einmaliger Prompt für einen One-Shot-Task braucht keine Spec; ein agentisches System, in dem Outputs zwischen Agenten weitergereicht werden, schon. Sobald zwei oder mehr Agenten kooperieren, ist die Spec nicht mehr nur Aufgabenbeschreibung, sondern Vertrag: Was übergibst du? Was darf der nächste Agent annehmen? Welche Invarianten hält die Pipeline? Felix Abele von codecentric formuliert das Pattern in seinem Praxisbericht zu Claude-Code-Workflows ziemlich präzise:
Communication between agents happens exclusively via files.
Die Spec im Dateisystem ist das Inter-Agent-Protokoll. Inline-Prompts skalieren da nicht.
Aus der Praxis: Persona-Synthese als SDG-Use-Case
Ich setze SDG gelegentlich ein – so auch in einem aktuellen Projekt, das ich aus NDA-Gründen anonymisiere. Die Aufgabe: hypothetische Datenlagen auf Basis etablierter sozialwissenschaftlicher Frameworks generieren – Big Five, Schwartz-Wertedimensionen, soziologische Milieumodelle, Konsum-Typologien aus der klassischen Marktforschung –, über MoE validieren und an nachgelagerte Aufgaben weiterreichen.
Das fing als einzelner, mittlerweile schmerzhaft langer Prompt an. „Generiere eine Datenlage mit folgenden Konstrukten, beachte folgende Bias-Constraints, vermeide folgende Trivialfälle …“ Spätestens ab dem dritten Validierungs-Durchgang wurde klar: Das ist kein Prompt mehr, das ist eine Spec, die nur so tut, als wäre sie ein Prompt. Und sie wurde mit jedem Iterationsschritt unhandlicher.
Die Umstellung war strukturell einfach, in der Wirkung aber deutlich. Aus dem Mega-Prompt wurden mehrere Artefakte: eine Datenlage-Spec mit definierten Pflichtfeldern, Edge-Cases, expliziten Bias-Constraints und Negativbeispielen für typische Fehlermuster. Eine Researcher-Spec, die definiert, wie ein Recherche-Agent aus Rohdaten passende Profile zieht. Und auf der Validierungsseite ein Mixture of Experts mit eigenen Specs pro Fachperspektive – Soziologie, Psychologie, Marketing, Ethik –, die parallel auf den Output schauen und jeweils gegen ihre eigene Domänen-Spec prüfen. Die Specs liegen im Filesystem, die Agenten greifen darauf zu, und der gesamte Output ist gegen die Specs auditierbar.
Was dabei am meisten überrascht hat: Der größte Gewinn lag nicht beim Modell. Er lag in der eigenen Klarheit. Wer eine Spec schreibt, in der Bias-Constraints und Edge-Cases stehen, muss vorher entscheiden, was denn nun „korrekt“ heißt. Diese Entscheidung fällt sonst implizit beim Reviewen, oft inkonsistent. Die Spec zwingt sie nach vorne.
Was die akademische Literatur dazu hergibt, ist anschlussfähig. Li, Chen, Namkoong und Peng aus Columbia („LLM Generated Persona is a Promise with a Catch“, 2025) beschreiben den methodischen Status quo nüchtern: Persona-Generierung mit LLMs basiert auf
ad hoc and heuristic generation techniques that do not guarantee methodological rigor or simulation precision, resulting in systematic biases in downstream tasks.
Die Forderung nach reproduzierbaren, transparenten Spec-Vorlagen ist im Kern eine Forderung nach SDG für diesen Use-Case. Die Roleplay-Studien zeigen denselben Befund aus anderer Richtung: Persona-LLMs ohne strukturelle Verankerung produzieren systematisch positive Response-Biases. Eine Spec mit verankerten Datenpunkten und expliziten Bias-Constraints ist die naheliegende Antwort – kein Selbstläufer, aber strukturell überlegen.
Die kritische Seite: Wo SDG kippt
Soweit die optimistische Lesart. Es gibt aber eine wachsende, ernstzunehmende Kritik aus der deutschsprachigen Praxis, und die sollte man kennen, bevor man SDG flächendeckend ausrollt.
Daniel Westheide schreibt bei INNOQ, SDD sei „Domain-Driven Design's impatient cousin“ – ein Pattern, das die gleichen Voraussetzungen wie DDD habe, nur ohne die Geduld dafür. Sein Befund ist scharf: „No knowledge, no spec.“ Eine Spec ist nicht besser als das Domänenwissen, das ihr Autor in den Raum bringt. Und: „Waterfall with a fresh coat of paint“ – der Plan-zuerst-dann-Code-Modus ist genau das Pattern, das wir mit guten Gründen jahrelang verlassen haben. Westheides Sweet Spot ist explizit der Solo-Founder, bei dem eine Person Domänenexperte, Product Owner und Entwickler in Personalunion ist. Skaliert auf Teams, die diese Rollen verteilen, bricht das Versprechen schnell.
Roman Stranghöner ergänzt das im INNOQ-Beitrag „Gute Last, schlechte Last“ aus einer anderen Richtung: Specs erzeugen Last. Manchmal hilft die – manchmal verlagert sie nur Komplexität, statt sie zu reduzieren.
Viele SDD-Frameworks investieren in der Planungsphase so, als wäre Iteration immer noch teuer. Aber das ist sie mit Agenten oft gar nicht mehr.
Wer mit einem fähigen Agenten arbeitet, kann ein Feature in drei kurzen Iterationsrunden bauen, statt eine stundenlange perfekte Vorab-Spec zu schleifen. Stranghöners Befund auf den Punkt gebracht: SDD reduziert Komplexität in der Denk-Phase, aber in der Bau-Phase wird daraus oft Dokumentations-Arbeit, die Feedback-Loops verlängert. Detaillierte Specs simulieren Klarheit, ohne geteiltes Verständnis im Team zu erzeugen.
Thoughtworks notiert im Tech Radar zu GitHub Spec Kit zwei verwandte Anti-Patterns: instruction bloat (immer mehr Projekt-Kontext landet im Agent-Instruction-Set, bis nichts mehr passt) und context rot (die Specs werden so umfangreich, dass das eigentliche Signal im Rauschen untergeht). Außerdem:
Defensive checks and overly verbose markdown outputs
Agenten beginnen, Spec-Konformität zu performen, statt nützliche Arbeit zu leisten.
Diese Kritik ist keine Widerlegung der Leitthese, aber sie ist die Bremsspur, die zur These dazugehört. SDG kippt zuverlässig, wenn die Spec größer wird, als die Aufgabe sie rechtfertigt. Wenn die Spec mehr Pflege braucht als der Code, den sie steuert. Wenn die Spec als Ersatz für fehlendes Domänenwissen herhalten soll, statt es zu codifizieren. Wenn Iteration billig ist und trotzdem so getan wird, als wäre sie teuer.
Eine pragmatische Heuristik
Aus den drei Achsen und der Kritiklinie lässt sich eine Regel herausarbeiten, die in der Praxis hilft. SDG ist dann ein Hebel und kein Klotz, wenn drei Bedingungen erfüllt sind: Die Aufgabe ist semi-formal spezifizierbar, also du kannst Acceptance Criteria nüchtern aufschreiben. Mindestens einer der drei Werte zeigt nach oben – kleines Modell, mehrere Agenten oder lange Lebensdauer der Aufgabe. Und die Spec passt vom Umfang her zur Aufgabe. Bei einem einzelnen, klar umrissenen Feature ist sie kompakt, nicht 1.070 Zeilen lang.
Wenn nur einer dieser drei Punkte fehlt, lohnt sich das Investment in eine Spec-Pipeline schon nicht mehr selbstverständlich. Wenn zwei davon fehlen, ist die Pipeline meistens Theater. Ein Frontier-Reasoning-Modell auf eine offene, kreative Aufgabe mit kompakter Lebensdauer loszulassen und es vorher mit einer 30-Seiten-Spec zu fesseln, ist nicht State of the Art, sondern Cargo Cult.
Was sich seit 2023/2024 wirklich verändert hat
Wer 2023 noch über Prompt Engineering gesprochen hat, spricht 2026 eher über Context Engineering. Tobi Lütke hat den Begriff am 18. Juni 2025 auf X geprägt; Karpathy und Simon Willison haben ihn binnen Tagen aufgenommen, Anthropic hat ihn am 29. September 2025 mit dem Engineering-Post „Effective context engineering for AI agents“ offizialisiert:
We are moving from finding the right words to engineering context.
Dieser Move ist nicht kosmetisch. Er beschreibt eine echte Verschiebung. Die Frage ist nicht mehr, welche Formulierung das Modell besser performen lässt, sondern welche Konfiguration aus Spec, Skills, AGENTS.md (oder was auch immer dein System so frisst), Plan-Files und Tool-Beschreibungen das Modell überhaupt erst in die Lage versetzt, die Aufgabe zu lösen. Specs sind in dieser Welt nicht der Anti-Hype gegen Reasoning-Modelle, sondern das Komplement zu ihnen: Sie liefern, was das Modell selbst nicht haben kann – projekt-, domänen- und organisationsspezifischen Kontext in maschinenlesbarer Form.
Eine konkrete Praxis-Verschiebung, die das illustriert: Bei Frontier-Modellen funktioniert weniger Spec-Prosa und mehr Constraints und Negativbeispiele. Anthropic empfiehlt für Skills explizit, dass „negative examples are extremely important – they define the boundaries of the feature and ensure it doesn't over-trigger“. Das ist eine andere Sorte Spec als die ausschweifenden Markdown-Dokumente, die einige der lauteren SDD-Frameworks produzieren. Schlanker, schärfer, näher an einem Vertrag und weiter weg von einer Doktorarbeit.
Mein Fazit
Spec-Driven Generation ist 2026 nicht der Heilsbringer, als der es in den lauteren Ecken der Bubble verkauft wird. Es ist aber auch nicht das Hype-Phänomen, das mit der nächsten Modellgeneration verschwindet. SDG hat sich vom Prompt-Trick zu einem Architektur-Pattern konsolidiert – mit einem klaren Anwendungskorridor, klar identifizierbaren Anti-Patterns und einer Tooling-Landschaft, die im letzten Jahr aus dem Experiment-Status in eine erste Reifephase gerutscht ist.
Wer mit kleineren Modellen arbeitet, wer agentische Pipelines baut, wer prozedurale Aufgaben mit klaren Acceptance Criteria automatisiert: für den ist SDG das, was es im Untertitel behauptet zu sein. Wer ein Frontier-Reasoning-Modell auf einen Single-Shot-Task wirft und vorher eine 30-Seiten-Spec schreibt: für den ist SDG genau das Cargo Cult, vor dem Westheide und Stranghöner zu Recht warnen.
Die Trennlinie ist nicht der Modell-Marketing-Stand. Sie verläuft entlang der drei Achsen oben. Wer die im Kopf hat, kann SDG produktiv einsetzen, ohne dem nächsten Hype hinterherzulaufen oder sich zu früh aus einem soliden Pattern zu verabschieden.
Wie das Pattern in zwei Jahren heißt, weiß ich nicht. Dass jemand den Begriff zwischendurch verbrennt, schon.