Metacognitive Scaffolding bei Reasoning-Modellen – wo „erst denken, dann antworten“ noch trägt
Das Modell soll vor der Antwort kurz planen, Annahmen offenlegen, Edge Cases benennen. Klingt vernünftig – und war es lange auch. Stand Juni 2026 ist die Antwort: Kommt drauf an. Und vor allem: Es geht nicht mehr um den Output, sondern um etwas anderes.
Metacognitive Scaffolding ist die Idee, ein LLM nicht direkt antworten zu lassen, sondern vorher eine kleine Planungsschicht einzuziehen – drei Annahmen, zwei Edge Cases, ein Satz Approach, dann der eigentliche Output. Der akademische Vorläufer ist Plan-and-Solve Prompting (Wang et al., ACL 2023): erst einen Plan entwerfen, dann nach Plan ausführen. Damit ließen sich auf GPT-3 die typischen Zero-Shot-CoT-Fehler reduzieren – Rechenfehler, fehlende Schritte, semantische Missverständnisse.
Ich habe diese Technik – wie Constraint-Based Prompting – in der Vor-Reasoning-Ära gerne eingesetzt: Brainstorming-Prompts, Analyse-Tasks, alles, wo das Modell vor lauter Antwortlust gerne den eigentlichen Auftrag übersprang. Hat geholfen, oft sogar deutlich. Heute? Selten so, wie es im Template steht.
TL;DR
Metacognitive Scaffolding – das Modell vor der Antwort drei Annahmen, zwei Edge Cases und einen Satz Approach formulieren lassen – war in der Vor-Reasoning-Ära ein verlässlicher Hebel. Heute hat die Technik einen neuen Job. Sie hilft nicht mehr beim Denken, sie dokumentiert es.
Frontier-Modelle wie GPT-5.5 oder Claude Opus 4.8 planen und prüfen Annahmen längst intern. Wer das klassische Template unverändert draufwirft, erzeugt dieselbe Prompting Inversion wie bei Constraint-Based Prompting: Das Modell hätte das Reasoning sowieso gemacht, jetzt produziert es zusätzlich eine formatierte Liste. Bei einem literal folgenden Claude Opus 4.8 kosten die „kein-dies, kein-das“-Regeln obendrein mehr, als sie bringen.
Drei Anwendungsfälle bleiben:
- Klassisch bei Non-Reasoning-Modellen (Haiku 4.5, Gemini 3 Flash, Mini-Varianten, GPT-5.x mit
reasoning="none") – ohne interne Reasoning-Tokens muss die Planung extern stattfinden. - Weglassen bei Frontier-Modellen auf Aufgaben, die niemand später prüft – Brainstorming, Einzelanalysen. Da ist „denk gründlich nach“ der bessere Hebel.
- Als Output-Vertrag dort, wo die Planung extern verfügbar sein muss – Compliance, Agenten-Handoffs, Debugging. Dann gehört die Struktur ins Output-Schema statt in eine Pre-Output-Phase – nicht „plane, bevor du antwortest“, sondern „dein Output enthält diese Felder“.
Der eigentliche Witz: Ausgerechnet Reasoning-Modelle erkennen laut AbstentionBench schlechter, dass sie etwas nicht wissen – der „(UNSICHER)“-Marker fängt also genau das nicht zuverlässiger ein, wofür er gedacht war.
Was Frontier-Modelle intern schon tun
Die aktuelle Generation – GPT-5.5, Claude Opus 4.8, Gemini 3.1 Pro – plant intern, prüft Annahmen intern, sucht intern nach Edge Cases. Anthropic schreibt das im offiziellen Claude-4.8-Prompting-Guide erfrischend direkt: Ein Prompt wie „think thoroughly“ produziere oft besseres Reasoning als ein handgeschriebener Step-by-Step-Plan. Claudes Reasoning übersteige häufig das, was ein Mensch vorschreiben würde.
OpenAI sagt im GPT-5.5-Guide dasselbe in API-Sprache: Erwartetes Ergebnis und Erfolgskriterien angeben, detaillierte Schritt-für-Schritt-Vorgaben reduzieren oder weglassen, dem Modell den Weg überlassen, wenn das Produkt nicht eine bestimmte Route erzwingt. „Describe the destination rather than every step.“
Wer ein klassisches Metacognitive-Scaffolding-Template – „liefere mir drei Annahmen, zwei Edge Cases, einen Satz Approach, dann den Output“ – unverändert auf Opus 4.8 loslässt, betreibt damit dasselbe, was beim CBP-Artikel die Prompting Inversion heißt: Externe Struktur überschreibt internalisierte Heuristiken. Das Modell hätte das Reasoning sowieso gemacht – aber jetzt muss es erst mal eine Liste produzieren, in der „(UNSICHER)“-Marker stecken sollen. Das ist Verwaltungsarbeit für eine Maschine, die das eigentliche Problem schon halb gelöst hatte.
Dazu kommt: Opus 4.8 folgt Anweisungen literaler als z.B. 4.6 – und Anthropic schreibt im selben Prompting-Guide explizit, dass positive Beispiele zuverlässiger funktionieren als negative Regeln. Das Template arbeitet aber zu einem nicht unerheblichen Teil mit negativen Regeln – „kein Overengineering“, „kein Metageschwafel“, „nicht raten, sondern ‚nicht angegeben' schreiben“. Bei 4.6 wurden solche Hinweise weich interpretiert. Seit 4.7 frisst jeder „kein“-Satz Tokens, ohne wirklich zu landen.
Wo Scaffolding trotzdem noch sinnvoll ist – und es ist nicht das, was man denkt
Die naheliegende Parallele zum CBP-Artikel wäre: Scaffolding gehört auf die kleinen, schnellen, non-thinking Modelle in Pipelines. Ähmmm, na ja – stimmt teilweise – aber die ganze Geschichte ist das nicht.
Erstens: Bei den kleinen Modellen – Claude Haiku 4.5, Gemini 3 Flash Preview, GPT-5.5-mini, OpenAIs GPT-5.1-„None“-Reasoning-Mode – funktioniert die alte Logik weiter. Wenn das Modell keine internen Reasoning-Tokens spendiert, muss die Planung extern stattfinden. OpenAI selbst empfiehlt im GPT-5.1-Guide explizit, dem Modell im non-reasoning-Modus zu sagen, es solle ausführlich planen, bevor es eine Funktion aufruft. Das ist klassisches Scaffolding – nur halt am richtigen Modell.
Zweitens, und das ist der eigentlich interessante Punkt: Es gibt einen Use-Case, in dem Scaffolding auch bei Frontier-Modellen einen Mehrwert hat, der mit Output-Qualität nichts zu tun hat: Auditierbarkeit.
Reasoning-Modelle denken intern. Was sie intern denken, ist mal sichtbar (als Reasoning-Trace), mal nicht (bei adaptivem Thinking auf niedrigen Effort-Stufen), und in jedem Fall nicht garantiert stabil. Wenn ein Output später in einem Compliance-Review, einem GxP-validierten Workflow oder einem Bug-Hunt rekonstruiert werden muss, ist „das Modell hat es schon irgendwie bedach“ keine Antwort. Da hilft es, die Annahmen und Edge Cases explizit als Teil des Outputs zu haben – nicht weil das Modell ohne diese Schritte schlechtere Antworten gäbe, sondern weil ohne sie keiner mehr nachvollziehen kann, warum die Antwort so aussieht.
Das Paper „LLM Driven Processes to Foster Explainable AI“ (Pehlke & Jansen, Nov 2025) formuliert genau das als Architekturprinzip: Reasoning in auditierbare Artefakte externalisieren, statt es als opaken Output zu konsumieren. Strukturierte Planungsblöcke sind dafür ein einfaches, robustes Mittel – aber sie dienen dann der nachgelagerten Inspektion, nicht der Inferenz-Qualität.
Eine zweite, ehrliche Differenzierung
Es gibt allerdings einen Forschungsbefund, der die einfache „Frontier braucht's nicht, Mini braucht's“-Geschichte etwas durcheinanderbringt. Das Think²-Paper (Februar 2026) hat strukturiertes metakognitives Prompting im Stil von Ann Browns Planning–Monitoring–Evaluation auf 8B-Modellen getestet – einmal mit Llama-3-8B als non-reasoning-Modell, einmal mit Qwen-3-8B als reasoning-getuntem Modell. Ergebnis: Beide profitieren, aber auf unterschiedliche Weise. Llama-3 zieht den Nutzen vor allem aus Diagnose-Tasks wie CorrectBench (68,14 % vs. 52,91 % Standard-Prompting) und TruthfulQA, wo die explizite Reflexion Halluzinationen nachweislich reduziert. Qwen-3 als reasoning-getuntes Modell absorbiert die metakognitive Struktur eher nahtlos in den ohnehin vorhandenen Reasoning-Trace.
Das stützt die These eher, als sie zu kippen: Es ist nicht primär eine Frage der Modellgröße, sondern eine Frage des Reasoning-Tunings und des Tasks. Wo das Modell ohnehin intern reflektiert, ist explizites Scaffolding redundant für die Qualität – wo es das nicht tut, oder wo der Task explizit Diagnose verlangt, hilft die Struktur.
Passend dazu ein Befund aus dem AbstentionBench: Reasoning-Modelle sind paradoxerweise schlechter darin zu erkennen, dass sie etwas nicht wissen, als non-reasoning Modelle. Genau die Selbsteinschätzung also, die ein „(UNSICHER)“-Marker einfangen soll, ist bei Frontier-Modellen nicht zuverlässiger geworden – sie ist es teilweise weniger. Das ist die kleine Pointe: Ausgerechnet die Modelle, denen wir am meisten Reasoning zutrauen, sind bei der Selbstdiagnose der Wissenslücken die schwächeren. Eine vergleichbare Asymmetrie – eine Prompt-Technik, die hilft, aber nicht für das, wofür sie ursprünglich beworben wurde – zeigt sich auch bei Verbalized Sampling und dem Mode-Collapse-Problem.
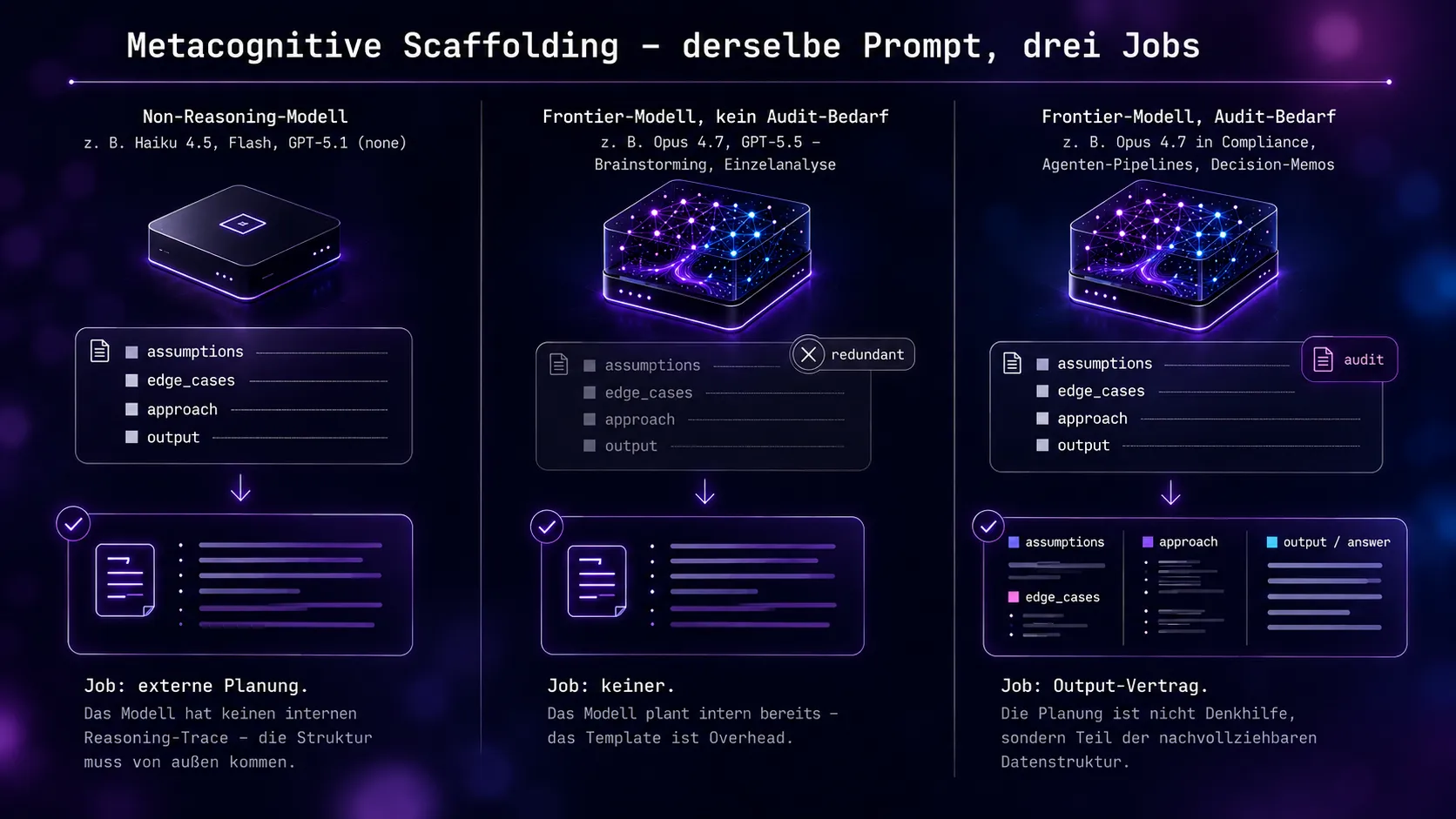
Was das fürs Template heißt
Wer das Template aus dem Briefing – drei Annahmen, zwei Edge Cases, ein Satz Approach – auf GPT-5.5 oder Opus 4.7 unverändert losschickt, tritt sich gleich zwei Effekte gleichzeitig ein: einen marginalen bis negativen Reasoning-Effekt (das Modell hätte das sowieso gemacht, jetzt muss es noch eine formatierte Liste produzieren) und einen positiven Audit-Effekt (die Annahmen stehen jetzt im Output, nicht nur im Reasoning-Trace).
Wenn der Audit-Effekt egal ist – Brainstorming, Kreativarbeit, einmalige Analyse – ist das Template Overhead. Dann ist „denk gründlich nach und sag mir die Antwort“ oder, bei OpenAI, ein höherer Effort-Level plus klarer Outcome-Spec der bessere Hebel.
Wenn der Audit-Effekt zählt – regulierte Branchen, mehrstufige Agenten-Pipelines mit Handoffs, Decision-Memos, alles, was später jemand prüfen oder ein anderes System weiterverarbeiten muss – dann ist das Template kein Reasoning-Hilfsmittel mehr, sondern ein Output-Vertrag. Und als Output-Vertrag sollte es auch formuliert sein: nicht „bevor du antwortest, plane bitte“, sondern „dein Output enthält folgende Felder“.
Eine modernisierte Fassung, die diesen Punkt sauber trifft, sieht – grob – so aus:
{
"role": "system",
"content": "Liefere ein JSON mit folgenden Feldern:\n- assumptions: 3 Stück, jeweils 1 Satz\n- edge_cases: 2 Stück, die für das Ergebnis relevant sind\n- approach: 1 Satz\n- output: das eigentliche Ergebnis im Format X\n\nFalls eine Annahme unklar ist, vermerke das im Feld assumptions selbst (z. B. 'unsicher, gewählte Standardannahme: ...'). Faktenregel: Nur bereitgestellte Daten verwenden; fehlende Daten als 'nicht angegeben' kennzeichnen."
}Drei Unterschiede zum Original-Template, die in einer Reasoning-Welt zählen: Erstens steht die Planung im Output-Schema nicht in einer Pre-Output-Phase – das macht klar, dass sie für die Nachvollziehbarkeit da ist, nicht für die Denkhilfe. Zweitens sind die negativen Anweisungen („kein Overengineering“, „kein Metageschwafel“) raus – die kosten bei Opus 4.7 mehr, als sie bringen. Drittens ist die Unsicherheit ins Feld selbst eingebaut, nicht in einen separaten Marker, der einer literal-folgenden 4.7 als Anweisung mehr Last als Nutzen wäre.
Und was nun?
Metacognitive Scaffolding klassisch anwenden – wie im Original-Template – bei Non-Reasoning-Modellen (Haiku, Flash, Mini-Varianten, GPT-5.1 mit reasoning="none", Mistral Small), bei Pipelines ohne menschliches Review, und überall, wo das Modell ohne externe Planung leicht den Auftrag verfehlt.
Scaffolding weglassen bei Frontier-Reasoning-Modellen auf Aufgaben, die ohnehin nur intern geprüft werden – kreative Arbeit, Einzelanalysen, alles ohne nachgelagerten Audit-Bedarf.
Scaffolding als Output-Vertrag formulieren, wenn die Planung extern verfügbar sein muss – für Compliance, Agenten-Handoffs, Debugging, Pipeline-Monitoring. Dann ist es kein Prompt-Trick mehr, sondern Teil der Datenstruktur.
Ladys und Gentlemen, was bleibt – und das ist die nicht-modellabhängige Hälfte der Geschichte: Wer drei Annahmen und zwei Edge Cases nicht selbst formulieren kann, hat kein Prompting-Problem. Der hat stumpf ein Briefing-Problem. Das Template zwingt einen, vor dem Modell die eigenen Anforderungen zu kennen. Das ist Denkwerkzeug, nicht Prompting-Trick – und es funktioniert modellunabhängig.
Im Modell-Stack selbst ist die Technik dagegen Kontextware. Auf einem Reasoning-Modell mit adaptivem Thinking heißt „planen vor dem Output“ inzwischen meist: dem Modell vertrauen, dass es das schon tut – und nur dann eingreifen, wenn man sehen muss, was es geplant hat.